페이지 분할은 데이터를 입력할 때 입력할 페이지 공간이 없어 2개 페이지로 데이터가 나눠지는 것을 의미
인덱스 검색은 클러스터형/보조 인덱스를 이용해서 데이터를 검색, 속도 빠름
2. 인덱스의 내부 작동
※핵심 키워드: 균형 트리, 페이지, 전체 테이블 검색, 페이지 분할, 인덱스 검색
클러스터형 인덱스, 보조 인덱스 모두 내부적으로 균형 트리(Balanced tree)로 만들어진다. 균형 트리는 자료 구조에 나오는 범용적으로 사용되는 데이터의 구조이다.
2-1. 인덱스의 내부 작동 원리
인덱스의 내부 작동 원리를 이해하면 인덱스를 사용해야 할 경우와 아닌 경우를 선택할 때 도움이 된다. 인덱스가 늘 좋은 것은 아니므로 정확히 판단하는 것이 중요하다.
균형 트리의 개념
균형 트리 구조에서 데이터가 저장되는 공간을 노드라고 한다. 참고로 MySQL에서는 페이지라고 부른다.
아래 그림에서는 총 4개의 노드를 표현했다. 하지만 데이터가 많다면 단계는 계속 많아질 수 있다.
MySQL에서는 페이지라고 부르며 페이지는 최소한의 저장 단위로 16K 크기를 가진다. 예를 들어 데이터를 1건만 입력해도 1개 페이지가 필요하다.
만약 데이터를 검색(SELECT)할 때 인덱스(균형트리)가 설정되어 있지 않다면 MMM을 찾기 위해서는 AAA ~ MMM까지 순차로 검색해야 그 결과를 알 수 있다.
하지마 인덱스(균형트리)가 설정되어 있다면 루트 페이지에서 AAA, FFF, LLL을 거쳐 리프 노드의 LLL, MMM을 거쳐 더 빠르게 찾을 수 있다
일반: 페이지 3개
인덱스: 페이지 2개
만약 데이터가 더 많다면 이 차이는 현저하게 발생할 것이다.
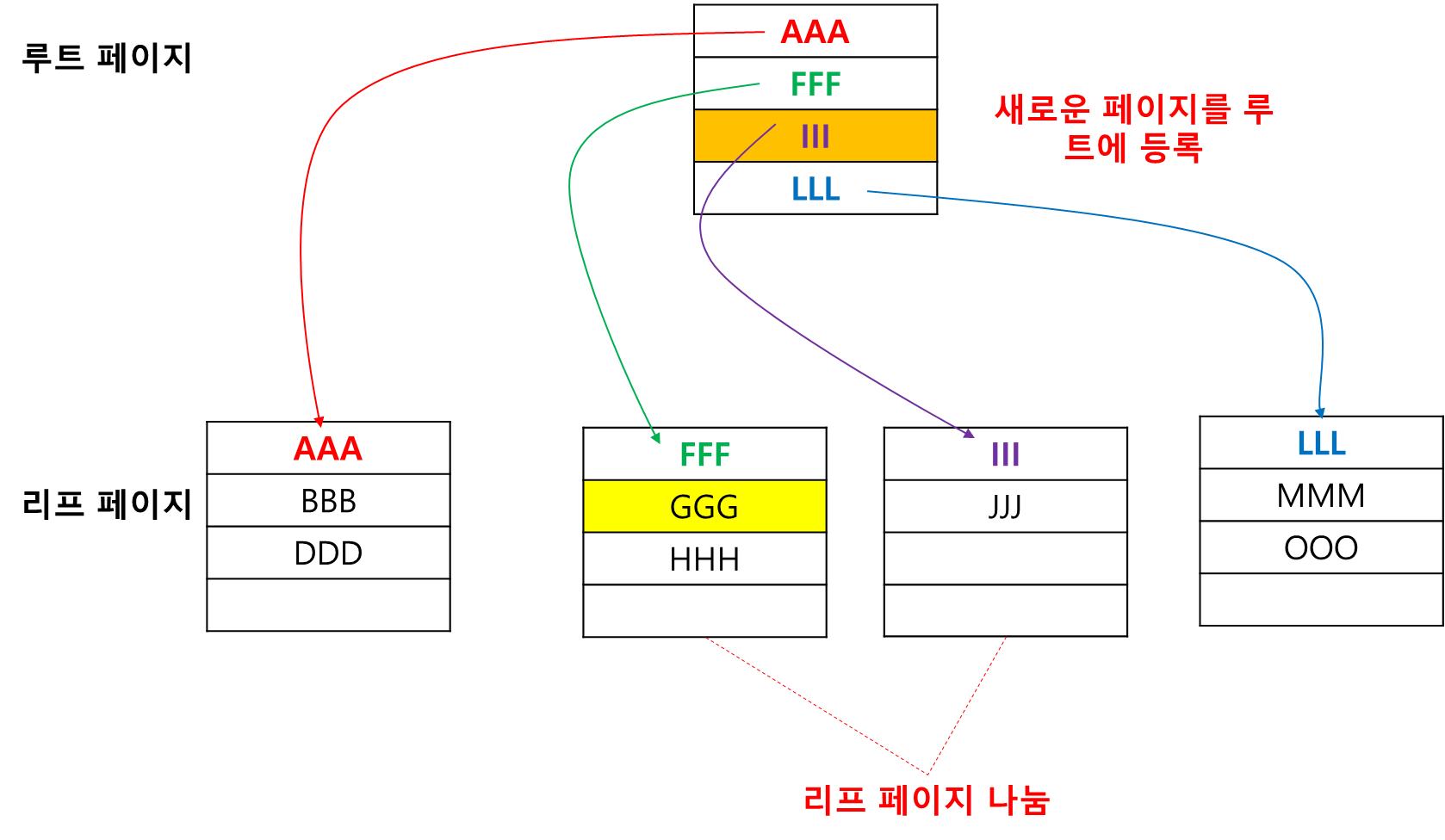
균형 트리의 페이지 분할
인덱스는 균형 트리로 구성되어 있어 SELECT의 속도를 향상 시킬 수 있다.
그런데 인덱스를 구성하면 데이터 변경 작업(INSERT, UPDATE, DELETE) 시 성능이 나빠진다. 이유는 페이지 분할이 일어나기 때문이다. 몇 가지 데이터를 INSERT하는 예제로 살펴보자.
우선 III 데이터를 입력해 보자. JJJ가 한 칸 아래로 이동되고 III가 삽입되었을 뿐 큰 변화는 이러나지 않았다.
이번에는 GGG를 입력해 보자. -GGG를 넣기 위해서는 리프에 페이지 공간이 부족하여 새로운 페이지를 만들어야 한다. -새로운 페이지가 생성되면 이를 루프페이지에도 등록해줘야 한다.
이번에는 PPP, QQQ를 두개 연속 입력해 보자. -PPP는 4번째 리프 페이지에 입력된다. -QQQ는 4번째 리프 페이지에 공간이 없으므로 리프 페이지가 추가된다. -루트 페이지에도 공간이 없으므로 페이지 분할이 일어나며 이것은 중간 페이지로 변경된다. -새로운 루트 페이지가 추가된다.
결국 QQQ 데이터를 입력하기 위해 3개의 새로운 페이지가 할당되고 2회의 페이지 분할이 일어났다. 즉 입력 작업이 오래걸리게 되었다. 이 예를 통해 인덱스를 구성하면 왜 데이터 변경(특히 INSERT) 작업이 느려지는지 확인할 수 있었다.
2-2. 인덱스의 구조
인덱스 구조를 통해 인덱스를 생성하면 왜 데이터가 정렬되는지 어떤 인덱스가 더 효율적인지 확인하자.
클러스터형 인덱스 구성하기
클러스터형 인덱스와 보조 인덱스의 구조는 어떻게 다른지 살펴보자. 우선 인덱스 없이 테이블을 생성하고 아래와 같이 데이터를 입력해 보자.
Use market_db;
CREATE TABLE cluster
( mem_id CHAR(8),
mem_name VARCHAR(10)
);
INSERT INTO cluster VALUES('TWC', '트와이스');
INSERT INTO cluster VALUES('BLK', '블랙핑크');
INSERT INTO cluster VALUES('WMN', '여자친구');
INSERT INTO cluster VALUES('OMY', '오마이걸');
INSERT INTO cluster VALUES('GRL', '소녀시대');
INSERT INTO cluster VALUES('IYZ', '잇지');
INSERT INTO cluster VALUES('RED', '레드벨벳');
INSERT INTO cluster VALUES('APN', '에이핑크');
INSERT INTO cluster VALUES('SPC', '우주소녀');
INSERT INTO cluster VALUES('MMU', '마마무');
실제 1페이지는 16K로 많은 데이터가 입력된다. 여기서는 1페이지에 4개의 행이 입력된다는 가정으로 살펴보자.
아직 인덱스가 없는 상태로 각 페이지 위에 써진 번호는 페이지 번호를 임의로 부여한 것이다.
실제 cluster 테이블을 살펴보면 입력된 순서대로 입력되었으므로 동일한 것을 알 수 있다.
페이지는 어떻게 변경될 지 생각해 보자. 기존 3개의 페이지는 mem_id를 기준으로 정렬되고 이것이 루트 페이지로 생성된다. 즉 영어사전과 같이 알파벳 순서로 구성된다. 가정된 사항은 리프를 제외하고는 7개의 데이터가 입력된다고 가정하였다.
보조 인덱스 구성하기
이번에는 보조 인덱스를 구성해 보자.
Use market_db;
CREATE TABLE second
( mem_id CHAR(8),
mem_name VARCHAR(10)
);
INSERT INTO second VALUES('TWC', '트와이스');
INSERT INTO second VALUES('BLK', '블랙핑크');
INSERT INTO second VALUES('WMN', '여자친구');
INSERT INTO second VALUES('OMY', '오마이걸');
INSERT INTO second VALUES('GRL', '소녀시대');
INSERT INTO second VALUES('IYZ', '잇지');
INSERT INTO second VALUES('RED', '레드벨벳');
INSERT INTO second VALUES('APN', '에이핑크');
INSERT INTO second VALUES('SPC', '우주소녀');
INSERT INTO second VALUES('MMU', '마마무');
ALTER TABLE second
ADD CONSTRAINT
UNIQUE (mem_id);
SELECT * FROM second;
# mem_id, mem_name
'TWC', '트와이스'
'BLK', '블랙핑크'
'WMN', '여자친구'
'OMY', '오마이걸'
'GRL', '소녀시대'
'IYZ', '잇지'
'RED', '레드벨벳'
'APN', '에이핑크'
'SPC', '우주소녀'
'MMU', '마마무'
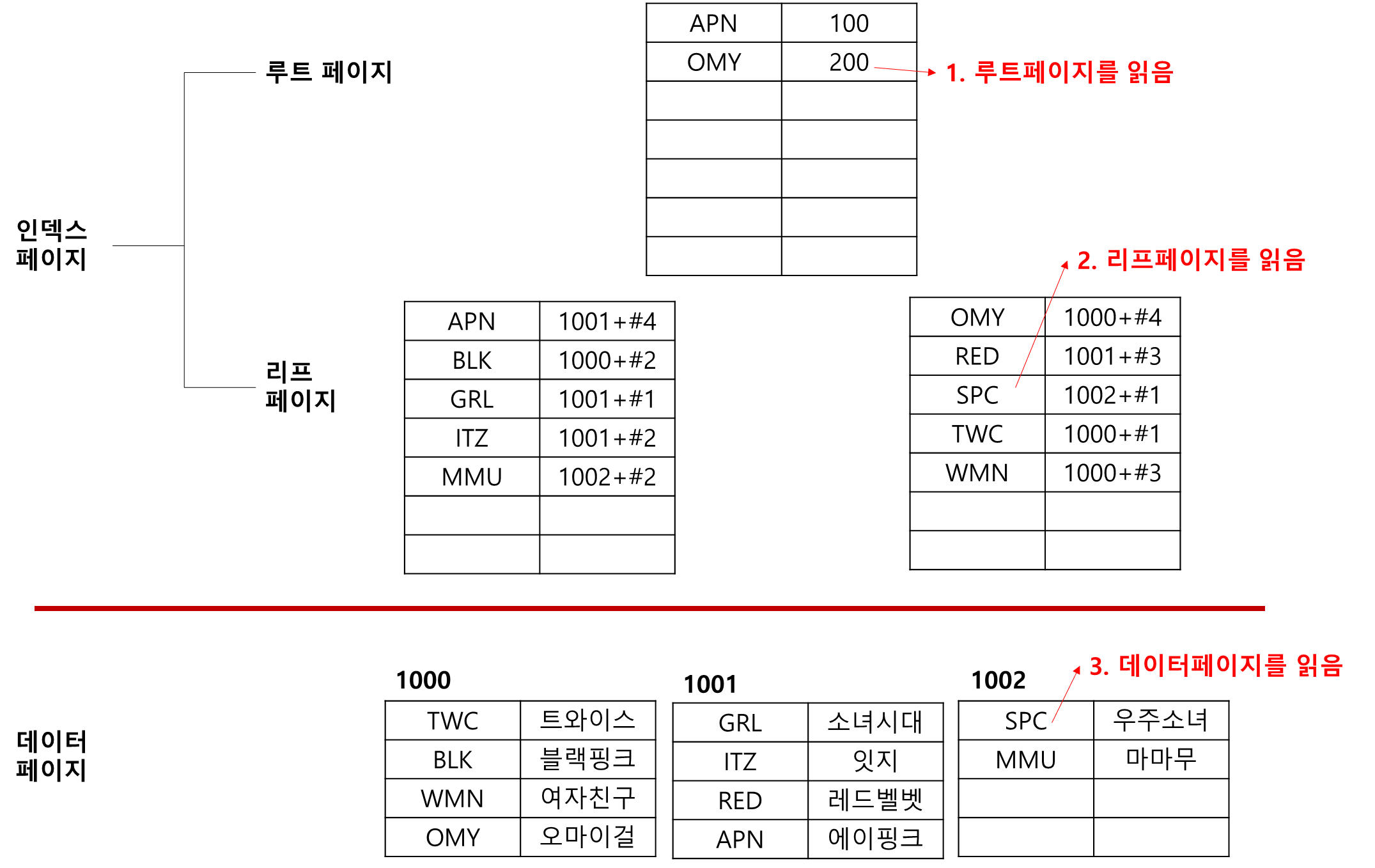
보조 인덱스는 일반적인 책과 비슷하다. 책의 뒷 공간에 찾아보기가 만들어진 것처럼 보조 인덱스가 별도의 공간에 만들어 진다.
데이터의 위치는 페이지 번호 + #위치로 기록되어 있다.
인덱스에서 데이터 검색하기
이제 데이터를 검색해 보자. 먼저 클러스터형 인덱스에서 검색을 해보자. 몇 개 페이지를 읽어야 가능한지 살펴봐 보자.